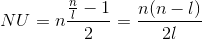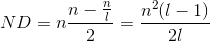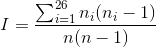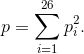
Questo test si basa principalmente su alcuni semplici calcoli di probabilità e sul
concetto di indice di coincidenza. Per ogni lingua esistono tabelle con la frequenza di
ogni lettera dell’alfabeto, consideriamo ad esempio l’alfabeto inglese e denotiamo
con p1
Consideriamo il solito testo cifrato abbastanza lungo, la probabilità che
in due posizioni qualsiasi si trovi la lettera di posizione con indice
, è
semplicemente ;
quindi in generale la probabilità che in due posizioni qualsiasi si trovi la stessa
lettera è data da
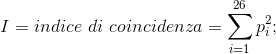
si osserva che questo indice di coincidenza cresce al crescere dell’irregolarità del
testo e diminuisce fino a 0,038 quando tutte le lettere sono equiprobabili, inoltre
l’indice è invariante per i cifrari monoalfabetici mentre tende a decrescere per i
cifrari polialfabetici.
Ovviamente per un testo cifrato con Vigènere si avrà un indice “più
piccolo” rispetto a quello di un cifrario monoalfabetico, che dipenderà
dalla lunghezza della chiave e mi permetterà di calcolare quanto vale
=lunghezza
chiave.
Un modo analogo per descrivere l’indice di coincidenza è il seguente: supponiamo di avere a
disposizione n lettere,
di cui ni è il numero
di lettere -esime,
e di volere sapere quale è il numero di coppie possibili formate da lettere uguali; allora questo
sarà dato da:
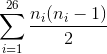 .
.
Quindi considerando una delle prime definizioni di probabilità, e cioè il numero
di casi possibili fratto il numero di casi favorevoli, ne verrà che la probabilità di
scegliere a caso una coppia di lettere uguale è:

 lettere; scegliamo a
caso una lettera tra
possibilità, questa mi identifica la colonna di appartenenza in cui avrò
lettere; scegliamo a
caso una lettera tra
possibilità, questa mi identifica la colonna di appartenenza in cui avrò
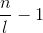 modi
per scegliere una seconda lettera, cioè il numero di coppie di lettere nella stessa
colonna è:
modi
per scegliere una seconda lettera, cioè il numero di coppie di lettere nella stessa
colonna è: