- Variabile casuale
- (o variabile aleatoria o variabile stocastica)
-
Non puoi aspettarti di vedere al primo sguardo. Osservare è per certi versi un'arte che bisogna apprendere.
(Friedrich Wilhelm Herschel)
Uno dei principali compiti di un ricercatore consiste nell'individuazione di una legge che meglio permetta di descrivere il fenomeno che sta indagando. Quando il fenomeno implica situazioni di incertezza (che portano quindi ad escludere modellizzazioni di tipo deterministico) ci si riconduce all'elaborazione di modelli probabilistici che consentono di interpretare le informazioni disponibili. La nozione di modello si riferisce generalmente ad una espressione matematica che, in qualche modo, riguarda la possibilità del verificarsi dei risultati di una situazione sperimentale astratta. Quando l'analisi della situazione reale permette di ricondurre il complesso delle informazioni raccolte ad uno schema interpretativo, corrispondente alle assunzioni che caratterizzano il modello astratto, è possibile per il ricercatore adottare il modello come strumento deduttivo.
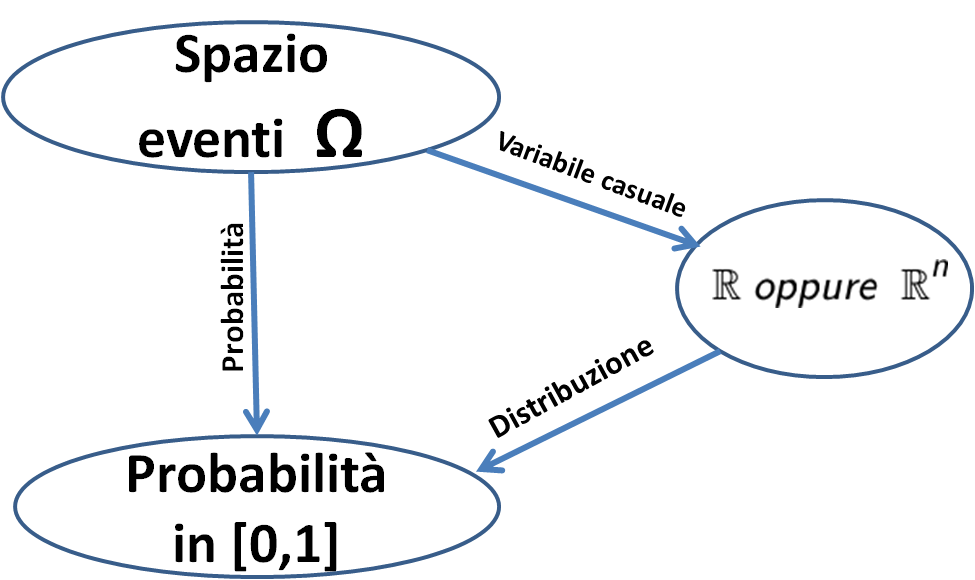
I modelli probabilistici sono di notevole interesse pratico perché propongono una precisa formulazione matematica di molte situazioni che si incontrano frequentemente nella realtà sperimentale. In molte situazioni reali, diverse tra loro, è possibile adottare lo stesso modello interpretativo, solo i parametri di tale modello varieranno in funzione del problema specifico.I risultati di certi esperimenti non sono necessariamente numerici, quali ad esempio il lancio di una moneta, o l'estrazione di una carta da un mazzo di carte francesi. E' molto scomodo trattare direttamente gli eventi e la trattazione diventa più semplice ed efficace se associamo delle quantità numeriche agli eventi. L'introduzione del concetto di variabile casuale (per brevità indicata a volte v.c. oppure v.a.) permette di tener conto proprio di questa esigenza, associando ad ogni risultato dell'esperimento un numero reale. Il vantaggio è quello di poter applicare alla risoluzione dei problemi di probabilità i potenti strumenti matematici.
Una variabile casuale X è una funzione definita sullo spazio campionario Ω che associa ad ogni elemento elementare
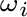 , un unico
numero:
, un unico
numero: 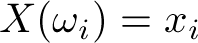 (
(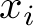 è una determinazione della variabile casuale X). L'attributo "casuale"
rinvia al fatto che essa è generata da un esperimento (o
meccanismo, o fenomeno naturale ecc.) di cui non siamo in grado di
prevedere l'esito con certezza.
è una determinazione della variabile casuale X). L'attributo "casuale"
rinvia al fatto che essa è generata da un esperimento (o
meccanismo, o fenomeno naturale ecc.) di cui non siamo in grado di
prevedere l'esito con certezza.La terminologia - seppur universalmente diffusa - è comunque ambigua. Da osservare che le variabili casuali non sono variabili, ma funzioni.
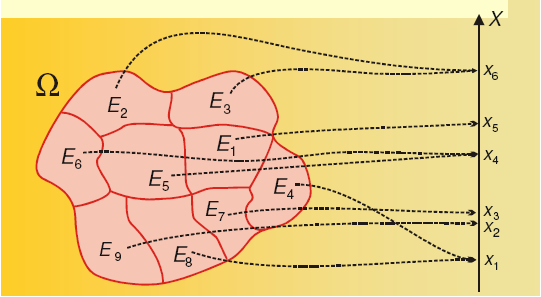
- Il
dominio della variabile casuale X (funzione) è dato dai punti
dello spazio campionario Ω.
- X: Ω → R

Otteniamo così, al posto dello spazio campionario Ω, che in genere è complesso, un semplice spazio campionario formato da un insieme di numeri. Il maggior vantaggio di questa sostituzione è che molte variabili casuali, definite su spazi campionari anche molto diversi tra loro, danno luogo ad una stessa "distribuzione" di probabilità sull'asse reale.
Le variabili casuali si indicano con lettere maiuscole ed i valori assunti con lettere minuscole.Alcuni esempi di variabili casuali:
- il numero di autovetture che attraversano in un giorno un certo casello autostradale;
- la velocità delle molecole di un gas contenuto in un recipiente;
- la durata di vita di una persona;
- il numero dei punti ottenuti con il lancio di due dadi;
- il guadagno (la perdita) che un giocatore realizza in n partite.
E' ovvio che non è possibile dire quale valore assumerà la variabile in ognuno di questi casi, è certo però che ne assumerà uno fra tutti quelli possibili. Ogni valore assunto dalla variabile dipende dal verificarsi o meno di un evento aleatorio.Le variabili casuali a una dimensione (cioè a valori in R) si dicono semplici o univariate.
Le variabili casuali a più dimensioni (cioè a valori in R²,R³... ) si dicono multiple o multivariate (doppie, triple, k-uple).
Un processo stocastico è un insieme ordinato di variabili casuali, indicizzate dal parametro t, spesso detto tempo, che rispondono a precise leggi probabilistiche. Anche se non è possibile individuare puntualmente la traiettoria del processo, tuttavia è possibile stimare l’obiettivo della traiettoria stessa.

VARIABILI CASUALI DISCRETE
Le variabili casuali sono discrete se possono assumere un insieme discreto (finito o numerabile) di numeri reali; in generale queste variabili producono risposte numeriche che derivano da un processo di conteggio (ad esempio: "il numero dei componenti della famiglia", "il numero di stanze in un albergo", ecc.)
VARIABILI CASUALI CONTINUE
Le variabili casuali sono continue se possono assumere tutti i valori compresi in un intervallo reale; in generale queste variabili producono risposte che derivano da un processo di misurazione (ad esempio "l'altezza", "il reddito", "il fatturato", ecc)
Mentre per una variabile discreta è possibile elencare tutti i valori che essa può assumere, per una variabile continua è necessario definire delle classi, cioè degli intervalli in cui suddividere i possibili valori della variabile.
La variabile continua è un concetto astratto: qualunque sia la precisione dello strumento, il numero di modalità ottenibili è discreto. Un errore frequente è quello di affermare che un carattere continuo (peso, tempo...) è discreto in quanto si osserva un insieme discreto di valori. Per esempio: una bilancia che misura alla precisione dell'hg fornisce valori come : 66,0 Kg; 66,1 Kg; 66,2 Kg .... i valori osservabili sono un insieme discreto, ma il carattere "peso" è continuo !
VARIABILI CASUALI MISTELa variabile casuale mista è in parte discreta e in parte continua. Un esempio lampante che si trova in natura è dato dai livelli energetici degli atomi. Secondo le leggi della meccanica quantistica l'energia di un elettrone in un atomo non è una quantità determinata (né determinabile) a priori ma è piuttosto una variabile casuale. Risulta dalla teoria (e viene confermato dagli esperimenti) che questa variabile casuale ha una distribuzione in parte discreta e in parte continua.
Osservazione:
Se lo spazio campionario Ω è discreto la variabile casuale sarà discreta mentre, se Ω è continuo, la variabile casuale può essere continua o discreta come evidenziato nell'esempio seguente.
Esempio 1:
Consideriamo una prova consistente nell'osservare l'altezza di un individuo. In tal caso Ω è continuo perché contiene un'infinità non numerabile di eventi (tutte le possibili altezze). La variabile casuale X "altezza" (espressa per esempio in cm) è una v.c. continua in quanto può assumere, almeno in teoria, qualsiasi valore nell'intervallo [20,300). Per esempio il valore 172,25 potrebbe corrispondere ad un individuo adulto, mentre 45,43 potrebbe corrispondere ad un neonato. Se però consideriamo due eventi E1= altezza superiore o uguale ai 150 cm ed E2 = altezza inferiore ai 150 cm, possiamo definire una variabile casuale X, che assume valore 1 in corrispondenza di E1 e valore 0 in corrispondenza di E2. In tal caso otteniamo una variabile casuale discreta.
Esempio 2:

Consideriamo l'esperimento del lancio di una moneta bilanciata. In questo caso Ω={testa,croce}; Ω:= {C,T}.
Consideriamo la variabile aleatoria così definita:X({testa}) = 1 e X({croce}) = 0Quindi: X:{testa,croce} → {0,1} il rango Sx = {0,1}
Che cosa è cambiato? Siamo passati da un insieme non numerico a un insieme numerico. Qual è il vantaggio?
Lanciamo 10 volte la moneta.rappresenta il numero di uscite di testa in 10 lanci.
Indichiamo con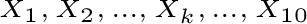 le variabili aleatorie corrispondenti a 10 lanci. Se vogliamo sapere il
numero di uscite di testa nei 10 lanci possiamo sommare i valori delle
10 variabili aleatorie. Quindi la variabile aleatoria X:
le variabili aleatorie corrispondenti a 10 lanci. Se vogliamo sapere il
numero di uscite di testa nei 10 lanci possiamo sommare i valori delle
10 variabili aleatorie. Quindi la variabile aleatoria X:
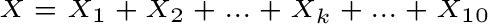
ovvero X = 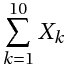
Esempio 3:
Consideriamo l'esperimento casuale del lancio contemporaneo di due monete. In questo caso Ω² sarà lo spazio campionario ottenuto dal prodotto cartesiano tra gli spazi dei singoli lanci, In simboli:Ω²= Ω x Ω:= {(C,C),(C,T), (T,C), (T,T)}.
Consideriamo la variabile aleatoria X dallo spazio campionario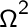 in R, che a ciascun punto campionario dello spazio, associa il numero di teste risultante.
in R, che a ciascun punto campionario dello spazio, associa il numero di teste risultante.
X: Ω² → R è una variabile casuale discreta, i suoi possibili valori sono:• 0 (se non si ottiene alcuna testa) X(C,C) =0
• 1 (se una delle due monete dà testa) X [(C,T),(T,C)]=1
• 2 (se entrambe le monete danno testa) X (T,T)=2
il rango SX = {0,1,2}
Dalle considerazioni e dagli esempi esposti finora, appare evidente il fatto che, qualora si voglia identificare una variabile casuale è necessario determinare due cose:
- l'insieme dei valori che la variabile casuale può assumere (insieme di valori costituito da un numero finito o infinito numerabile di numeri reali per le variabile discrete oppure un numero infinito non numerabile di numeri reali, per le variabili continue)
- il modo in cui la probabilità si distribuisce (si "spalma") su questi valori. Può essere determinato in tre modi:
- 1) attraverso la funzione di massa (o funzione di probabilità) definita solo per le variabili casuali discrete. La funzione di massa o di probabilità, la si può incontrare anche con la notazione PMF, dall'inglese "Probability Mass Function".
- 2) attraverso la funzione di densità - definita solo per le variabili casuali continue . La funzione di densità, la si può incontrare anche con la notazione PDF, dall'inglese: "Probability Density Function".
- 3) attraverso la funzione di ripartizione (o funzione di distribuzione o delle probabilità cumulate) - definita sia per le variabili casuali discrete che per le continue. La funzione di ripartizione la si può incontrare anche con la notazione CDF, dall'inglese "Cumulative Distribution Function ".
Una distribuzione di probabilità è un modello matematico che collega il valore di una variabile alla probabilità che tale valore si trovi all’interno della popolazione ovvero possa essere osservata. Ne consegue che l’esito di una misura può essere considerato una variabile casuale, poiché tale valore può assumere valori differenti all’interno della popolazione.
Ognuno dei risultati di una variabile casuale è associato ad una determinata probabilità. La funzione che associa ad ogni valore della variabile una probabilità corrispondente si chiama "distribuzione di probabilità" oppure "legge di probabilità".
distribuzione di probabilità:={ (x,f(x)) | x
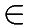 dom} dove f(x) è la funzione di massa di probabilità oppure la funzione di densità di probabilità.
dom} dove f(x) è la funzione di massa di probabilità oppure la funzione di densità di probabilità.
Le variabili casuali che emergono, interpretando distinte situazioni reali, vengono così ad essere descritte da distribuzioni di probabilità che possono essere studiate ed algebricamente manipolate, indipendentemente dalle loro specifiche applicazioni.
La scelta del modello della distribuzione di probabilità da adattare ad un particolare problema, molto spesso, è condotta per mezzo del confronto tra la forma dell'istogramma dei dati osservati e la forma della funzione di massa (PMF), funzione di densità (PDF) o funzione di ripartizione (CDF) di una particolare distribuzione nota. A volte questo esame può essere l'unico approccio al problema, ma è da sottolineare che le conclusioni a cui si arriverà saranno tanto più errate, tanto più le assunzioni del modello di base sono lontane dal descrivere e interpretare la situazione reale. E' quindi auspicabile che la scelta del modello si basi principalmente sulla comprensione del fenomeno.
La variabile casuale trasforma in numeri il risultato di un esperimento casuale; ma poiché tali risultati sono frutto del caso, anche i valori che la variabile casuale assume sono frutto del caso. Ne possiamo conoscere il valore solo dopo che l'esperimento è stato effettuato, a priori possiamo sapere al massimo i valori che la variabile casuale assume e con quale probabilità. Conoscere queste due cose significa conoscere completamente la variabile casuale; infatti la distribuzione identifica la variabile casuale, nel senso che ne descrive completamente il massimo che possiamo conoscere della variabile casuale: il suo comportamento probabilistico.
Per particolari esigenze si può essere interessati non alla distribuzione della variabile casuale considerata, ma più semplicemente a delle descrizioni sintetiche della stessa, che tramite pochi valori ci permetta di cogliere le caratteristiche essenziali della distribuzione, anziché procedere ad una sua rappresentazione completa mediante la funzione di ripartizione, la funzione di massa o la funzione di densità. In questo ipertesto saranno presentati alcuni di questi indici caratteristici: il valore atteso (o media o speranza matematica) e varianza. Altri indici caratteristici sono: moda e mediana.
Osservazione: E’ possibile associare una variabile casuale a qualsiasi fenomeno o esperimento casuale anche nel caso in cui il risultato non sia esprimibile numericamente.In questi casi se E è l’evento, si considera la variabile X che può assumere il valore 1 se l’evento E si verifica e il valore 0 se l’evento E non si verifica.
Indicando con p la probabilità che l’evento E si verifichi e con 1-p la probabilità che non si verifichi, si ha la seguente tabella:
X
P
0
1
1 - p
La variabile X così formata è detta variabile indicatrice dell’evento E. La variabile casuale indicatrice costruita in questo modo è una variabile casuale discreta, in quanto assume solo i valori 0 e 1 con la probabilità P(X=1) = p e P(X=0) = 1 - p. Dunque è possibile costruire variabili casuali discrete su un qualunque spazio di probabilità (discreto o continuo). Osserviamo infatti che se Ω è uno spazio di probabilità discreto, tutte le variabili casuali costruite su Ω saranno necessariamente discrete. Se invece Ω è uno spazio di probabilità continuo su di esso è possibile costruire sia variabile aleatorie continue che discrete (e ovviamente anche miste).

 Torna all'Indice
Torna all'Indice  pagina successiva
pagina successiva